膨張畳込み(Dilated Convolutions)
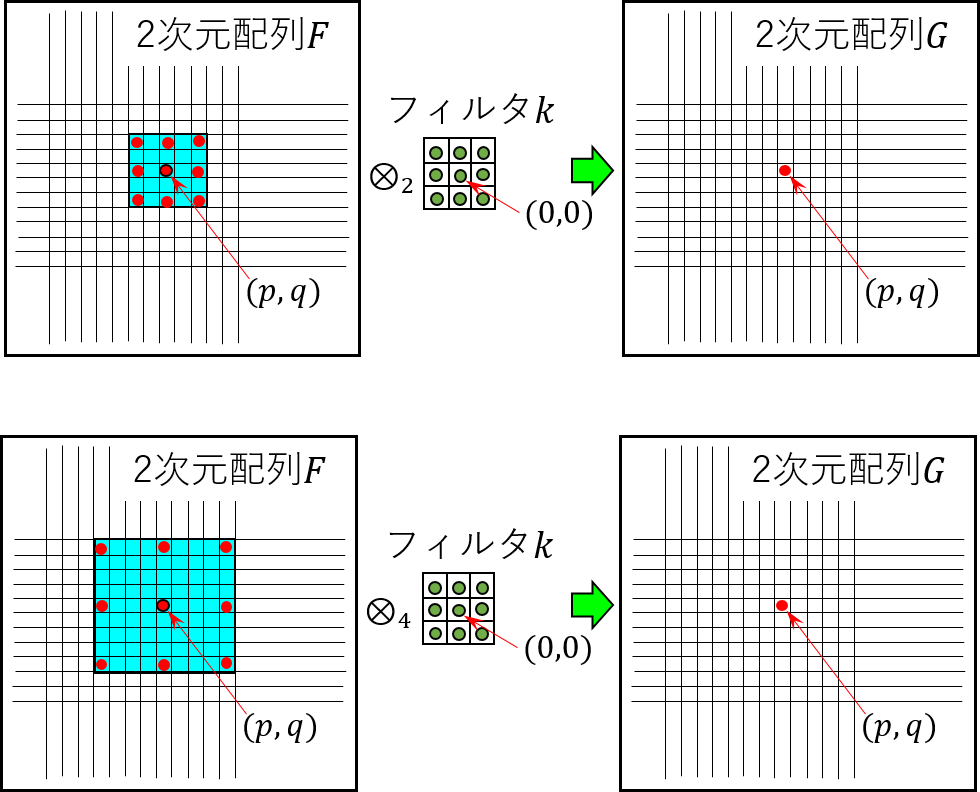
$F:\Bbb {Z^2}\rightarrow \Bbb{R}$を離散関数、$\Omega_r=[-r,r]^2\cap \Bbb{Z^2}$とし、 $k:\Omega_r\rightarrow \Bbb{R}$を$(2r+1)\times (2r+1)$の大きさの離散フィルタとするとき、 離散畳み込み演算子$\otimes$は以下の様に表されます。 \begin{equation} G(\boldsymbol p)=(F \otimes k) (\boldsymbol p) = \sum_{\boldsymbol{s+t=p}} F(\boldsymbol s)k(\boldsymbol t). \end{equation} この式表現から畳込み処理をイメージすることが難しい場合は、$\boldsymbol{s = p-t}$として 以下の様に表現し直すと良いかもしれません。 \begin{equation} G(\boldsymbol p)= \sum_{\boldsymbol t}F(\boldsymbol{p-t})k(\boldsymbol t) \\ \end{equation} さらに、入出力の位置ベクトルを2次元座標系の $\boldsymbol p =(n_1,n_2),\boldsymbol t=(m_1,m_2)$ で表すと、通常用いられる離散系の畳込み演算を表す式が得られます。 \begin{equation} G(n_1,n_2) = \sum_{m_1=-r}^{r}\sum_{m_2=-r}^{r}F(n_1-m_1,n_2-m_2)\cdot k(m_1,m_2) \end{equation}続いて、ある正の整数$l$を用いて上式の畳込み演算を一般化します。すなわち、 \begin{equation} (F \otimes_l k)(\boldsymbol p) = \sum_{\boldsymbol s + l\boldsymbol t = p} F(\boldsymbol s)k(\boldsymbol t) \end{equation} この式を前述の畳込み演算の表現式で表すと以下の様になります。 \begin{equation} G(n_1,n_2) = \sum_{m_1=-r}^{r}\sum_{m_2=-r}^{r}F(n_1-l\times m_1,n_2-l\times m_2) \cdot k(m_1,m_2) \end{equation} 積和演算変数$m_1$と$m_2$に関して、関数$F$とフィルタ$k$のドメインの変位量に注目すると、 フィルタ$k$においては変数の変位量に応じたフィルタ係数が取り出されますが、関数$F$に対しては、 変数$m_1$と$m_2$それぞれ$l$倍された変位量の位置での関数値が参照されることを示しています。 関数$F$を2次元座標上に配置された画像と考え、膨張畳込み処理の概念を図として表したのが、次の 図6-1です。$F$を入力画像、$k$を$3\times 3$のフィルタとし、$\otimes_2$と$\otimes_4$ の膨張畳込み処理において、ある点$(p,q)$での畳込み計算結果を求める流れを表しています。 $F$中の水色矩形領域が受容野を表し、受容野中の各赤丸点とフィルタの対応する各係数との積和が $G$中の$(p,q)$座標に格納されます。式ではそれぞれ、以下の様に表されます。ただし、入力画像 については右下端を原点とし、上および左方向を正の向きとする座標系、フィルタについては フィルタ中心を原点に右および上方向を正の向きとする座標系とします。パラメータ$l$は膨張係数 と呼ばれています。膨張係数を大きくしていくと、入力配列に対する受容野が指数的に増大していくことが 分かります。すなわち、同じフィルタに対して積和を取る2次元配列の要素の位置が広がっていきます。
Kerasでは、Conv1D、Conv2DおよびConv3Dにおいて膨張畳込みがサポートされています。 いずれも、'dilation_rate'キーワードによって膨張率を指定することができ、 指定がない場合はデフォルトで1とみなされます。 簡単な例で膨張畳込み処理を確認しておきます。
import numpy as np
import tensorflow as tf
from tensorflow import keras
from keras.layers import Input, Conv2D
from keras.models import Model
from keras import initializers
X1 = Input(shape=(7,7,1))
Y1 = Conv2D(1, kernel_size=(3,3),dilation_rate=2,padding='same',
kernel_initializer=initializers.Ones()) (X1)
model_1 = Model(inputs=[X1], outputs=[Y1])
#入力信号の設定
x = np.zeros(49,dtype=np.int32).reshape(1,7,7,1)
x[0,3,3,0] = 1
#入力信号xに対する出力の計算
y =model_1.predict(x)
#入出力テンソルの次元数確認
print('入力テンソルの次元数:',x.shape)
print('出力テンソルの次元数:',y.shape)
x_ba,x_row,x_col,x_ch = x.shape[0:4]
y_ba,y_row,y_col,y_ch = y.shape[0:4]
print('****** 評価結果 *****')
print(y.reshape(y_row,y_col).astype(np.int32))
(5x5)-標準カーネル
1 0 1 0 1
0 0 0 0 0
1 0 1 0 1
0 0 0 0 0
1 0 1 0 1
上記で定義したネットワークモデル'model_1'はサイズ7x7の2次元配列1チャネルを入力とし、出力もサイズ7x7の1チャネル となる2次元システムと見ることができます。モデルに入力された実際のデータと、 model_1.predict()のメソッド実行によって得られた出力データの2次元配列(入出力マップ)は 以下の様になります。
入力マップ
[[0 0 0 0 0 0 0]
[0 0 0 0 0 0 0]
[0 0 0 0 0 0 0]
[0 0 0 1 0 0 0]
[0 0 0 0 0 0 0]
[0 0 0 0 0 0 0]
[0 0 0 0 0 0 0]]
出力マップ
[[0 0 0 0 0 0 0]
[0 1 0 1 0 1 0]
[0 0 0 0 0 0 0]
[0 1 0 1 0 1 0]
[0 0 0 0 0 0 0]
[0 1 0 1 0 1 0]
[0 0 0 0 0 0 0]]
文脈情報の多重化
濃密予測の効率化を図る場合、文脈情報を多重化して収集することが有効です。 様々な種類の文脈情報が考えられますが、この節で扱う文脈情報は受容野を変化させた場合の 畳込み演算による特徴マップを対象とします。前述したように、膨張畳込みでは物理的な解像度を 下げることなく、受容野を拡大した特徴マップを作成することができます。 従って、膨張率を変化させて膨張畳込み処理を行い、その結果を直接マージすることで、 文脈情報の多重化が可能となります。 文脈の多重化について述べる前に、モデルの各層を表すパラメータの扱いについて簡単に触れます。 学習を行わずに所望の畳込みフィルタを得ようとすると、モデル定義の段階で初期値として パラメータを設定する必要があります。この初期値設定に必要な情報の確認から入ります。 フィルタのパラメータは2種類のデータ、 すなわちカーネルの各要素の係数(重み)と活性化関数の閾値で構成されています。 以下のKerasを利用した簡単なモデル定義の例について考えます。
import cv2
import numpy as np
import tensorflow as tf
from tensorflow import keras
from keras.layers import Input, Conv2D, Concatenate
from keras.models import Model
from keras import initializers
from matplotlib import pyplot as plt
X0 = Input(shape=(256,256,1),name='input')
X1 = Conv2D(64,(3,3),padding='same',name='conv_1')(X0)
X2 = Conv2D(1, (1,1),padding='same',name='conv_2')(X1)
model_2 = Model(inputs=[X0], outputs=[X2])
model_2.summary()
Model: "model_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input (InputLayer) (None, 256, 256, 1) 0
_________________________________________________________________
conv_1 (Conv2D) (None, 256, 256, 64) 640
_________________________________________________________________
conv_2 (Conv2D) (None, 256, 256, 1) 65
=================================================================
Total params: 705
Trainable params: 705
Non-trainable params: 0
_________________________________________________________________
L1 = model.layers[1]
W1 = L1.get_weights()
print(W1[0].shape)
print(W1[1].shape)
(3,3,1,64)
(64,)
レイヤー1のConv2D層では、カーネルサイズ3x3の大きさを持つ畳込みフィルタが64個分、 また活性化関数の閾値もフィルタ数分だけ確保されていることが分かります。 レイヤー2も畳込み層ですが、カーネルサイズは1x1であり、入力マップ内での畳込み効果はありません。 代わりに入力マップのチャネル間の積和をとります。この層についても、重み係数の内部表現構造を求めてみます。
W2=model.layers[2].get_weights()
print(W2[0].shape)
print(W2[1].shape)
(1,1,64,1)
(1,)
となります。これで、 フィルタの初期値データの表現構造について確認することができました。
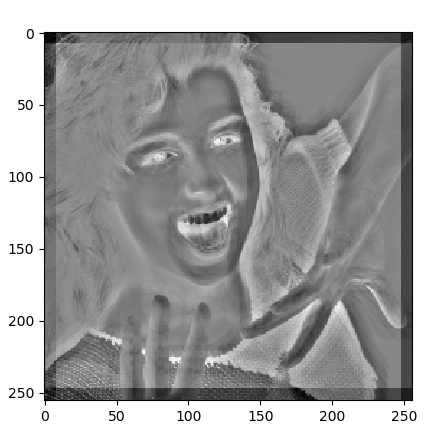
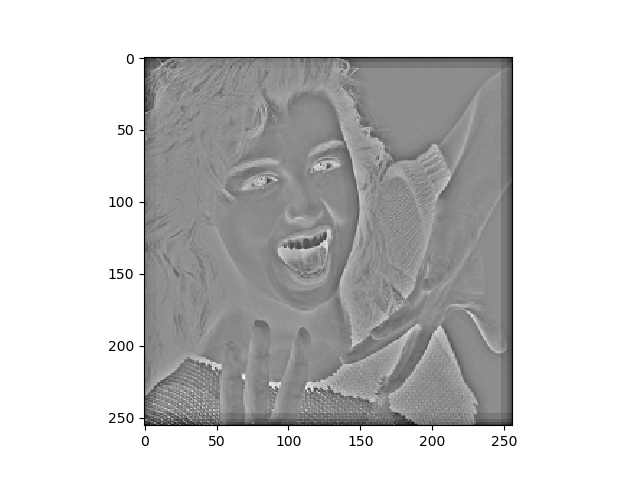
以上の内容を踏まえ、画像処理でよく用いられる3x3のラプラシアンフィルタを畳込み層の中に 作成します。即ち、ラプラシアンフィルタとして用いられる3x3のマスクの各要素を、numpy型4次元配列'kernel_0' として与えます。 また、異なるdilation_rateで膨張畳込みを行った結果を統合するための1x1の畳込み層の初期値を 同じくnumpy型4次元配列'kernel_1'として定義します。 ここでは、それぞれの膨張畳込み結果を均等に統合する重み係数とします。
####### 入力画像の設定と読込 #######
img_path ='sample1.pgm'
x = cv2.imread(img_path,0) #画像の読み込み(白黒階調画像)
x = x/255.0 #画素値を[0,1]に正規化
x = x.reshape(*x.shape,1) #チャネル情報を追加
####### 畳込み層の重み係数設定 #######
kernel_0 = np.array([1,1,1,1,-8,1,1,1,1]).reshape(3,3,1,1)
kernel_1 = np.array([1,1,1,1]).reshape(1,1,4,1)
####### ネットワークモデルの定義 #######
X0 = Input(shape=(x.shape))
X1 = Conv2D(1,(3,3),padding='same',name='conv_1',dilation_rate=1,
kernel_initializer=initializers.Constant(kernel_0))(X0)
X2 = Conv2D(1,(3,3),padding='same',name='conv_2',dilation_rate=2,
kernel_initializer=initializers.Constant(kernel_0))(X0)
X3 = Conv2D(1,(3,3),padding='same',name='conv_3',dilation_rate=4,
kernel_initializer=initializers.Constant(kernel_0))(X0)
X4 = Conv2D(1,(3,3),padding='same',name='conv_4',dilation_rate=8,
kernel_initializer=initializers.Constant(kernel_0))(X0)
Y0 = Concatenate()([X1,X2,X3,X4])
Y1 = Conv2D(1,(1,1),padding='same',name='bottle_neck',
kernel_initializer=initializers.Constant(kernel_1))(Y0)
M = [] #モデルのリスト表現
M.append(Model(inputs=[X0], outputs=[X1]))
M.append(Model(inputs=[X0], outputs=[X2]))
M.append(Model(inputs=[X0], outputs=[X3]))
M.append(Model(inputs=[X0], outputs=[X4]))
M.append(Model(inputs=[X0], outputs=[Y1]))
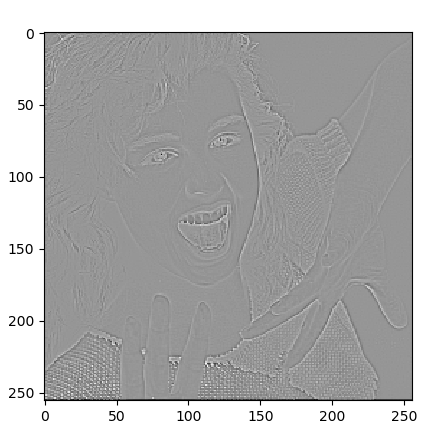
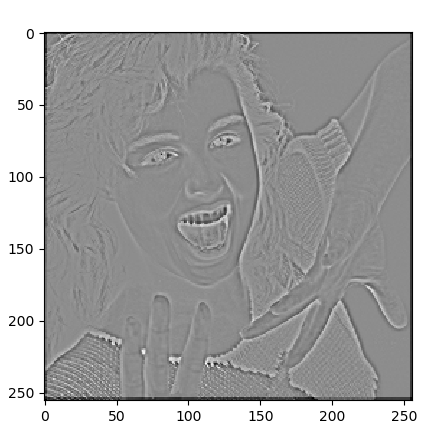
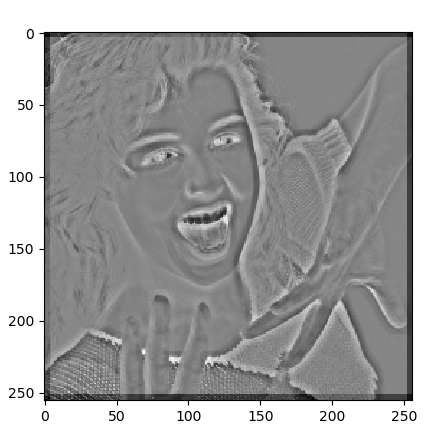
###### 畳込み処理の実行と出力表示 ######
x = x.reshape(1,*x.shape) #バッチ数1を設定
y = []
for i in range(5):
y.append(M[i].predict(x)) #各モデルの予測実行
for i in range(5): #各予測結果の画像表示
z = y[i].reshape(y[i].shape[1:3])
plt.imshow(z,cmap='gray')
plt.show()
########### 多重化処理の終了 ###########
参考資料
- Fisher Yu and Vladlen Koltun, 'Mult-Scale Context Aggregation By Dilated Convolutions' ICLR (2016) arXiv:1511.07122v3[cs.CV]
- Liang-Chieh Chen, George Papandreou,Iasonas Kokkinos Kevin Murphy and Alan L. Yuille, 'DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs', arXiv:1606.00915v2[cs.CV] 12 May 2017
- https://qiita.com/nishiha/items/e9dfaa941a8902c95d01 'Grad-CAMとdilated convolution'
- http://joisino.hatenablog.com/entry/2017/07/13/210000 'Dilated Convolution'