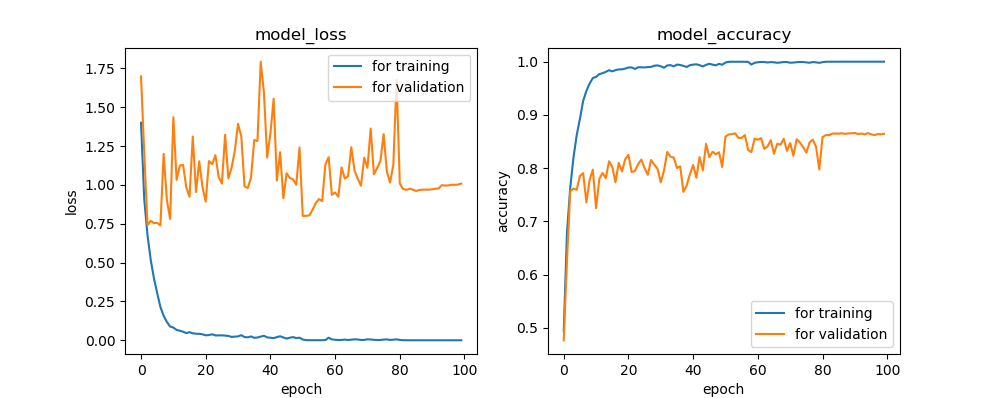
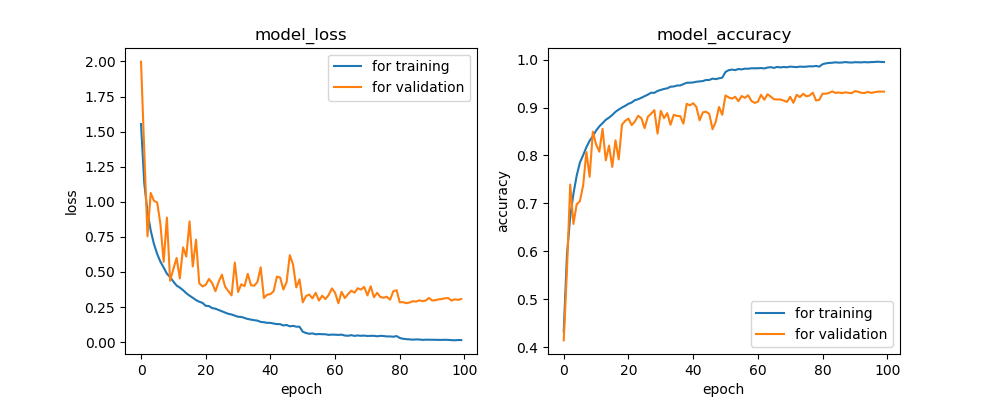
公開されているデータセットCIFAR-10を例に、データ拡張を行った場合と行わない場合とで、 学習状況および学習後の分類精度にどんな違いが出てくるかを検証してみます。 分類実験に用いたネットワークは、18層で構成されるResidual Network(ResNet)モデルです。 以下の図6.1にResNet18のレイヤー構造を示します。2つのブロック構造を組み合わせることで ネットワークを構成しています。ブロックの内部構造に関しては、レイヤーの順序を変えたり、 プーリング層を挿入するなどのバリエーションもありますが、 ここでは以下のような、4つの畳込み層を持つ構造を持つネットワークを対象とします。
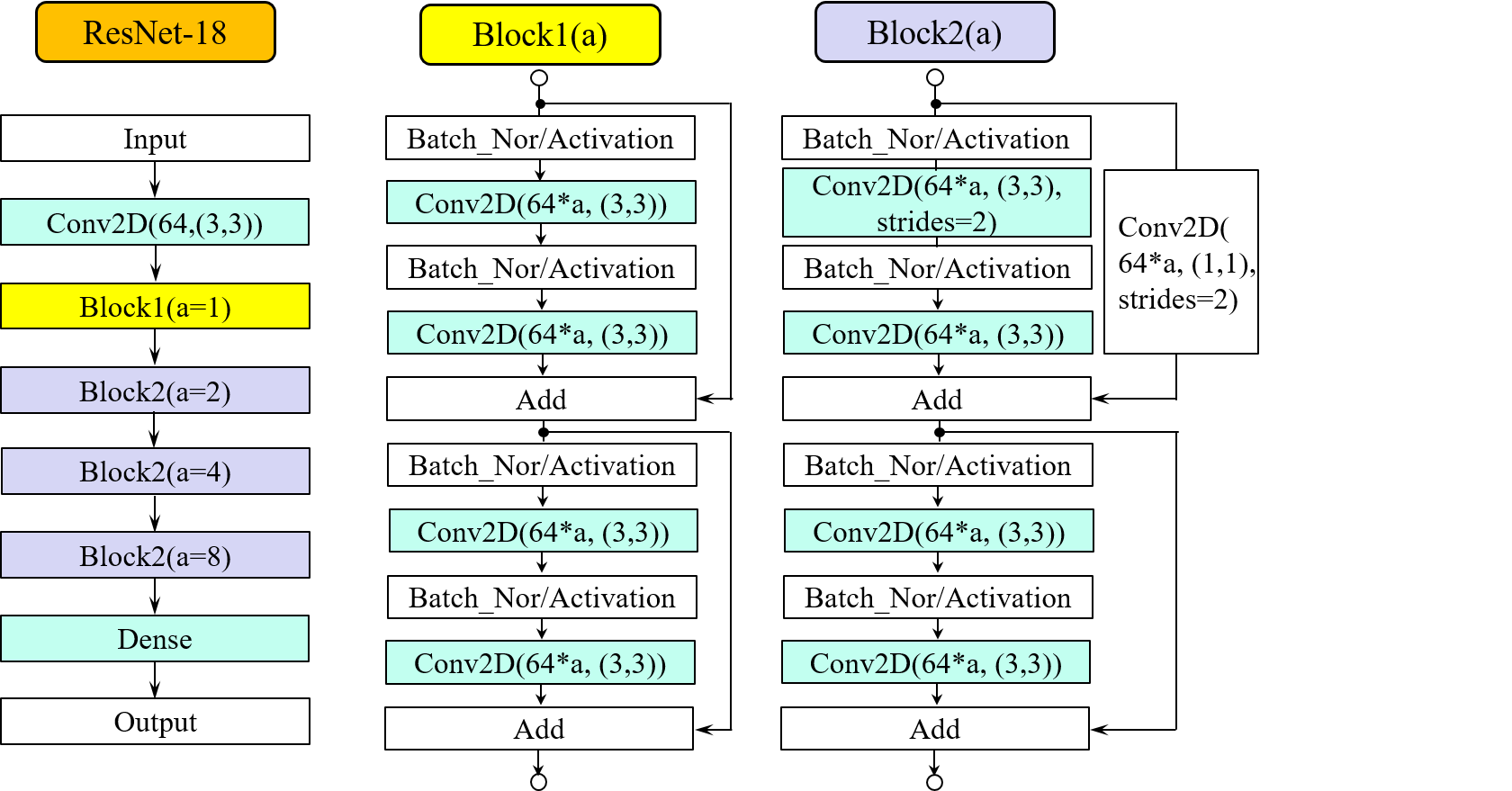
図6.1に示したネットワークモデルのレイヤー構造に忠実にコード表現した例が次のプログラムです。 Block1、Block2とも、2つの畳込み層が縦続接続された経路とそのショートカット経路という基本 単位を2度繰り返す構成となっています。この基本構成数をブロック毎に表すと[2,2,2,2] さらに、Block2の最初のショートカットには、カーネルサイズ(1x1)の畳込み層が挿入されています。 これは、ショートカット経路に並列な縦続接続経路の最初の畳込み層で指定されている'strides=(2,2)' によって、演算後の特徴マップの解像度が2分の1になることを受けてのことです。すなわち、 縦続接続経路を通ることでブロックの基本単位に対する入出力特徴マップの物理的解像度 (マップの縦と横のサイズ、およびチャネル数)が変化するため、 ショートカット側でも入出力マップの物理的解像度を合わせる必要があるためです。 従って、特徴マップをBlock2に1回通せば、その解像度は半分になるということが言えます。
######################################################################
# ResNet-18モデル定義 #
######################################################################
def Block1(X,a):
short_cut = X
X = BatchNormalization()(X)
X = Activation('relu')(X)
X = Conv2D(64*a,(3,3), padding='same',kernel_initializer='he_normal')(X)
X = BatchNormalization()(X)
X = Activation('relu')(X)
X = Conv2D(64*a,(3,3), padding='same',kernel_initializer='he_normal')(X)
X = Add()([X, short_cut])
short_cut = X
X = BatchNormalization()(X)
X = Activation('relu')(X)
X = Conv2D(64*a,(3,3), padding='same',kernel_initializer='he_normal')(X)
X = BatchNormalization()(X)
X = Activation('relu')(X)
X = Conv2D(64*a,(3,3), padding='same',kernel_initializer='he_normal')(X)
X = Add()([X,short_cut])
return X
def Block2(X,a):
short_cut = Conv2D(64*a,(1,1), strides=(2,2),kernel_initializer='he_normal')(X)
X = BatchNormalization()(X)
X = Activation('relu')(X)
X = Conv2D(64*a,(3,3), strides=(2,2),padding='same',kernel_initializer='he_normal')(X)
X = BatchNormalization()(X)
X = Activation('relu')(X)
X = Conv2D(64*a,(3,3), padding='same',kernel_initializer='he_normal')(X)
X = Add()([X, short_cut])
short_cut = X
X = BatchNormalization()(X)
X = Activation('relu')(X)
X = Conv2D(64*a,(3,3), padding='same',kernel_initializer='he_normal')(X)
X = BatchNormalization()(X)
X = Activation('relu')(X)
X = Conv2D(64*a,(3,3), padding='same',kernel_initializer='he_normal')(X)
X = Add()([X,short_cut])
return X
def resnet18(input_shape):
input = Input(shape=input_shape)
X = Conv2D(64,(3,3),padding='same',kernel_initializer='he_normal')(input)
X = Block1(X, a=1)
X = Block2(X, a=2)
X = Block2(X, a=4)
X = Block2(X, a=8)
X = BatchNormalization()(X)
X = Activation('relu')(X)
X = GlobalAveragePooling2D()(X)
X = Dropout(0.5)(X)
output = Dense(10,activation='softmax')(X)
model = Model(inputs=[input], outputs=[output])
return model
######################################################################
# ResNet-18モデル定義(1) #
######################################################################
def resnet(num_blocks, wide):
num_filters = 64
input = Input(shape=(32,32,3), dtype=tf.float32)
X = input
X = Conv2D(num_filters,(3,3), padding='same', kernel_initializer='he_normal')(X)
short_cut = X
X = BatchNormalization()(X)
for i,blocks in enumerate(num_blocks):
for j in range(blocks):
if i > 0 and j == 0:
short_cut=Conv2D(num_filters,(1,1), strides=(2,2),
kernel_initializer='he_normal')(short_cut)
X = Activation('relu')(X)
X = Conv2D(num_filters,(3,3), strides=(2,2), padding='same',
kernel_initializer='he_normal')(X)
X = BatchNormalization()(X)
else:
X = Activation('relu')(X)
X = Conv2D(num_filters,(3,3), padding='same',
kernel_initializer='he_normal')(X)
X = BatchNormalization()(X)
X = Activation('relu')(X)
X = Conv2D(num_filters,(3,3), padding='same',
kernel_initializer='he_normal')(X)
#ショートカットとのマージ
X = Add()([X, short_cut])
short_cut = X
X = BatchNormalization()(X)
#end of FOR j
num_filters *= wide
#end of FOR i
#全結合
X = Activation('relu')(X)
X = GlobalAveragePooling2D()(X)
X = Dropout(0.5)(X)
y = Dense(10,activation='softmax')(X)
#モデル生成
model = Model(inputs=[input], outputs=[y])
return model #生成したモデルを返す
#resnet()定義終了
データ拡張の有無による学習への影響について