ResNetとは
ニューラルネットの学習においては、一般にネットワークの深さを単純に深くしていくと、 学習効率が下がってしまうという劣化問題が発生します。そのため、2014年当時のImageNet コンペティションの画像認識部門で世界トップを獲得したVGGNetモデルの層数は19層、 物体検出部門1位のGoogleNetは22層でした。それぞれに層数を変えて性能比較を行ったと考えられますが、 層数に見合う精度向上が得られませんでした。 そこで考え出されたのが、ネットワークの入出力に関して 条件を付与することでした。ネットワークの基本モジュールが 持つべき潜在的写像関数を$H(x)$($x$はモジュールへの入力)とするとき、このモジュールの 出力として$F(x):= H(x)-x$と拘束条件を与えます。すなわち、モジュールの潜在的写像関数の出力と 入力との残差を関数$F(x)$として定義します。 この関係を変形すると、$H(x)=F(x)+x$と表されることから、 入力$x$、写像関数$H(x)$と$F(x)$の関係を図として表現すると図5-1のように表されます。
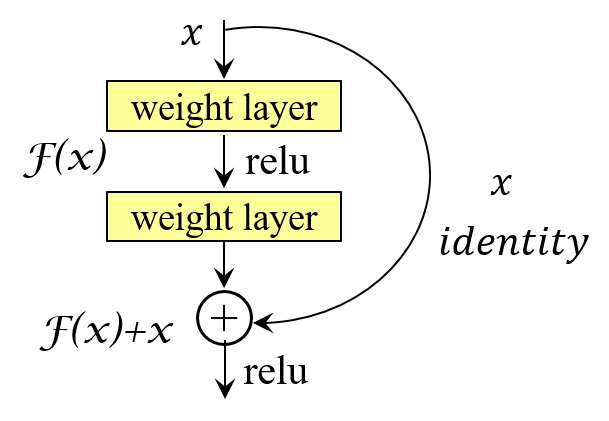
もし、潜在的写像関数による変換値が入力値から大幅に変化していなければ、その残余$F(x)$は0に近い値となります。 $F(x)$の学習は、モジュールの出力が入力値からどれだけ変位しているかを見つけることであり、 その入力は直接的に与えられるため、比較的容易に学習を行うことができると予想されます。 ネットワークが、図5-1に示したような基本モジュールの多数接続で構成されている場合、 1つ1つの基本モジュールは比較的小さな変化を担えばよいことになります。 このような学習は残余学習(residual learning)とも言われます。 図5-1の入力から出力への直接接続はショートカット接続(shortcut connection)と呼ばれ、 1層あるいはそれ以上の畳込み層をスキップして入力を出力に直接渡す恒等写像(identity mapping) の役割を担います。
一方、図5-2は、学習の必要なパラメータを持つ畳込み層を積み重ねて構成した残余関数モジュールを示しています。 左側のモジュールは、$3\times 3$のフィルタカーネル64個から成る畳込み層を2重に重ねたものです。 このモジュールへの入力をサイズ$56\times 56$、64枚の特徴マップ(図中、$x(56,56,64)$と表現) としたときの出力マップの次元数は、 入力と同じく$(56,56,64)$です。すなわち、 基本モジュールを通る前後で入力と出力マップの次元数は変化しません。 一方、 右側のモジュールの例は、入力マップの次元数が$(14,14,256)$の場合です。 こちらの場合もモジュールの入出力マップの次元数は同じとしますが、基本モジュールの構造としては 畳込み層を3重に重ねたものになっています。 第1層と第3層のフィルタカーネルのサイズは$1\times 1$です。 $14\times 14$、256チャネルの入力マップを受け取る基本モジュールの第1層、 および第2層のチャネル数は64と、チャネル数を絞り込む構造になっています。 このモジュールへの入力マップの次元数を$(14,14,256)$、出力も同じ次元数のマップとして、 各畳込み層での乗算回数を求めてみます。 \[ 第1層:1 \times 1 \times 14 \times 14 \times 256 \times 64 = 3,211,264 \] \[ 第2層:3 \times 3 \times 14 \times 14 \times 64 \times 64 = 7,225,344 \] \[ 第3層:1 \times 1 \times 14 \times 14 \times 64 \times 256 = 3,211,264 \] 合計すると、$13,647,872$となります。 もし、 第2層のカーネルサイズ$3\times 3$のフィルタだけで入力と同じ次元数の出力マップを生成しようとすると、 フィルタのチャネル数を256個としなければなりません。従って、その場合の畳込み層で行われる乗算回数は、 \[3 \times 3 \times 14 \times 14 \times 256 \times 256 = 115,605,504 \] となり、前述の3層重ねに対して約8.5倍の乗算回数が必要になることが分かります。 3層重ね型における第1層の畳込み層は256のチャネル数を64チャネルに変換する役割を持ち、第3層の 畳込み層は64チャネルを256チャネルに拡張する役割を果たしています。大きなチャネル数を小さくした上で 本来の目的とする畳込み演算を行い、その後に元のチャネル数に戻すという構造になっています。 このような構造をボトルネック(bottle_neck)構造とも呼んでいます。
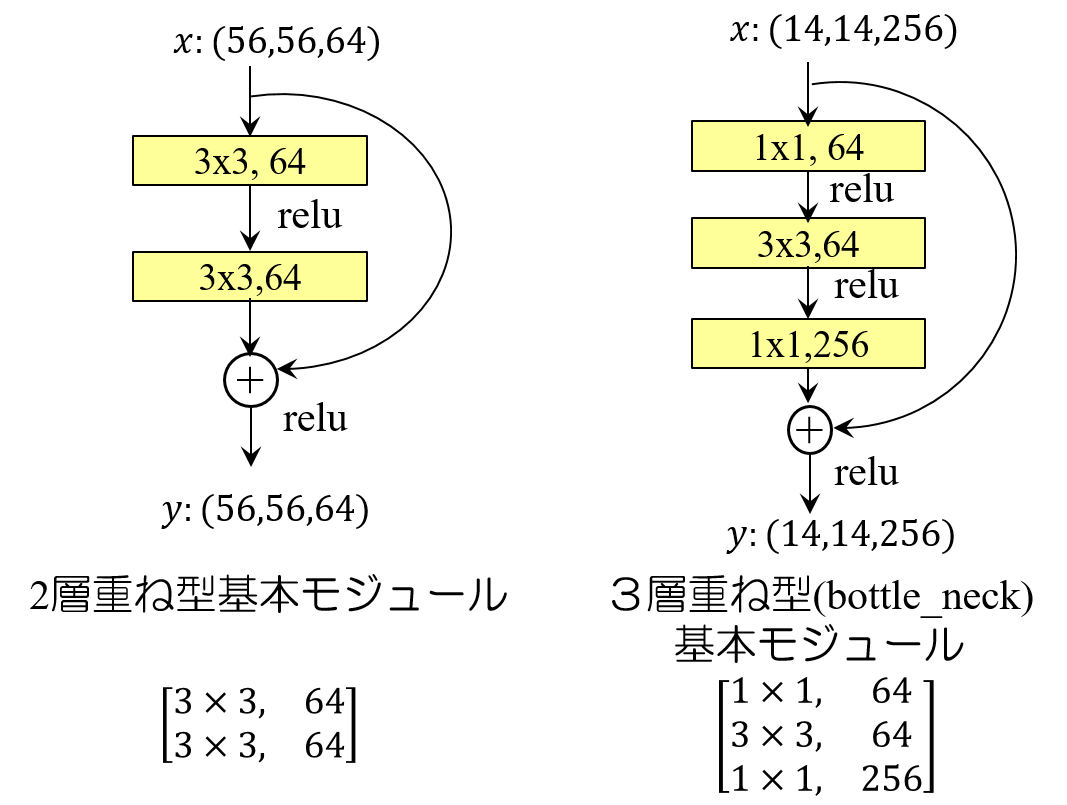
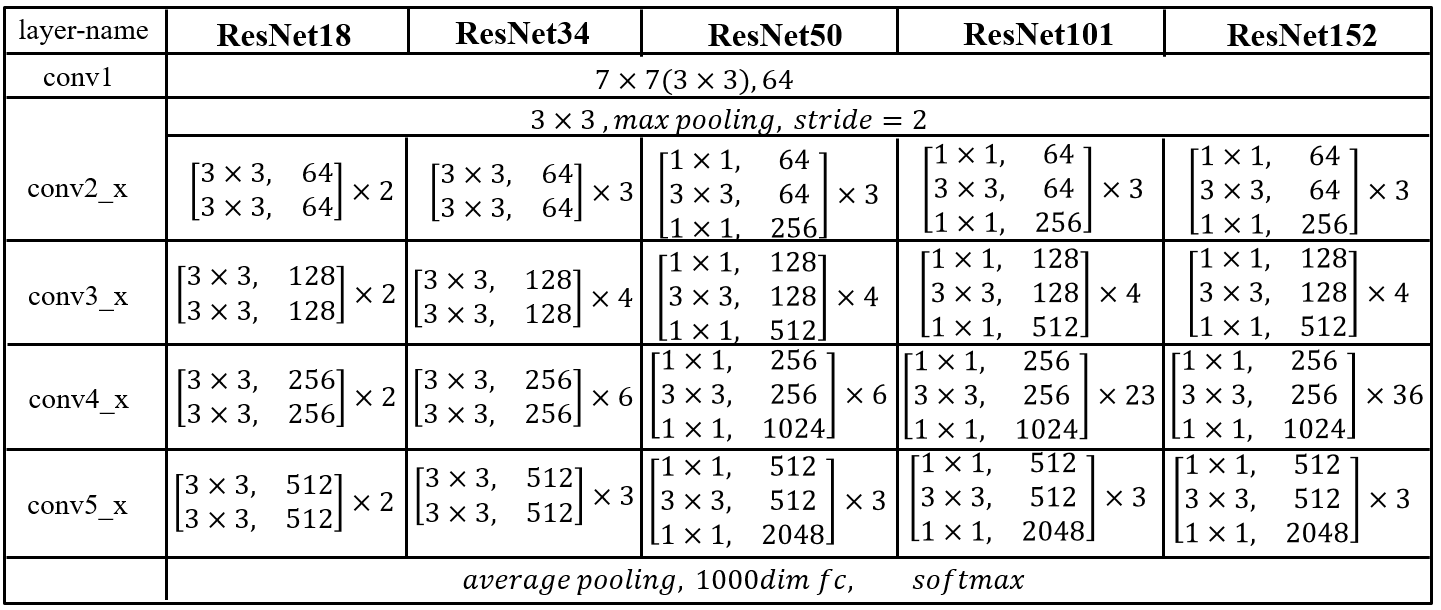
図5-1に示したような基本モジュールを積み重ねることで得られるネットワークをResNet(Residual Network)と 呼んでいます。 基本モジュールの選択および重ねるモジュールの数に応じて何種類かのResNetが提案されていますが、 実験的には1000層を超える極めて深い畳込み層ネットワークの構築が可能であることが報告されています。 図5-3は、基本モジュールの重ね回数に応じて定義されているネットワークの種類とその構成をまとめたものです。 同図からも分かるように、基本モジュールの重ね具合に応じて、'ResNet18'、'ResNet34'、 'ResNet50'、'ResNet101'、'ResNet152'と名付けられた5つのタイプがしばしば引用されます。 ’ResNet’に続く数値は各モデルに含まれる学習すべきパラメータを含む層数を示しています。
一方、いずれのタイプも、全体の構成が5つのブロックに分けられています。 図中、'conv1'、'conv2'、'conv3'、'conv4'、'conv5'のラベルでブロック1からブロック5までを 表しています。一般に、各ブロックの畳込み層におけるフィルタの数(チャネル数)は、 モジュールに入力される画像の大きさに応じて選択されます。 ResNetを提唱した原著では、 ImageNetデータセットに登録されている対象オブジェクトの中から選択された1000クラスの オブジェクトを分類する課題を扱っており、ネットワークへの入力は$224\times 224$ の3チャネルカラー画像です。CIFAR-10データセットのようにサイズが小さい画像を対象とする場合は、 チャネル数も少なくして用いられます。
ブロック5からの出力は、 全結合層1層を経て各オブジェクトのカテゴリーの確信度を表す1000個のユニットへと流れていきます。 また、 ブロック2からブロック5までは、それぞれのタイプによって基本モジュールの数も異なっています。
ブロック5に続くは部分は、解決すべき問題に依存しますが、 ブロック1からブロック5までは一般的に画像特徴のエンコード処理として利用可能です。 ResNet構造はエンコード処理の性能もよいため、各種のAIプラットホーム上でモジュール化されています。 KerasではResNet50を利用可能です。
それぞれのプラットフォームでモジュール化されたResNetは、
ImageNetプロジェクトで作成されたデータセットに基づいて学習が行われています。
従って、ImageNetプロジェクトでの収集が十分でない対象の分類や分割を行いたい場合は、
解決すべき問題に応じたResNetモデルの定義とデータセットの準備および学習が必要になります。
図5-1あるいは5-2に示した基本モジュールは学習が必要な畳込み層のみを表していますが、
実際のネットワークでは、畳込み層の他に活性化層やプーリング層、バッチデータの正規化を行う層
(Batch Normalization)などを挿入する必要があります。
これまでの議論からも分かるように、ResNetの中核となる層は畳込み層です。
複数の畳込み層を含むネットワークという観点から見た場合、
畳込み層以外の正規化層や活性化層の位置関係をどのようにするのかという疑問が湧いてきます。
しかし、
畳込み層以外の層をどのような順でどこに挿入するかを決定する理論的手順はなく、ターゲット
となるデータセットに応じて試行錯誤的に決定することが行われています。
最初に、活性化層と正規化層との前後関係について考えてみます。
通常、正規化処理はデータ全体の平均と分散が一定になるようにデータの変換を行います。一方、
活性化層は、例えばreluのように、畳込み層への入力に非負条件やりミッタ制限を付与するなどを目的とします。
活性化後に正規化処理を施す場合、活性化の目的を反故にするような事態が起こり得ます。
従って、正規化後に活性化処理を行うのが順当な順番でしょう。
一方、図5-1からも分かるように、入力からのショートカットと畳込み処理との加算処理が実行されますが、
この加算処理に対する正規化処理および活性化処理の位置取り選択も、
学習効率に影響を与えると考えられます。
一連のシーケンスにおけるそれぞれの層の位置取りに関しても検証が行われており、中でも
図5-4に示すレイヤーのシーケンスが高い学習効率を示したことが報告されています。

文献[2]中の検証では、畳込みを行う前に正規化および活性化を行う(pre-activation)場合と、 畳込み後に正規化と活性化を行う(post-activation)場合について比較を行い、 活性化および正規化を畳込み処理の前に行ったほうが良い結果を得たと述べています。 さらに、このシーケンスは全体の層数が増えるほど認識効率が良くなることも述べられています。
Wide Residual Networks
文献[2]では、基本モジュール内での畳込み層に対する正規化層や活性化層の位置関係に注目した ネットワークの評価が中心でしたが、視点を変え、ネットワークの深さを固定してネットワークの広さに 注目した評価を行っているのが文献[4]です。すなわち、深さを抑える代わりに畳込み層における チャネル数を増やした場合(Wide Residual Networks)の性能を評価しようとしたものです。 残余ネットワークは、その層数を増していくことによって認識精度の向上が期待されますが、 層数の増加に伴うコスト、具体的には学習時間が急激に増加するという問題が生じます。 畳込み層におけるフィルタカーネルの数を増やせば、層数を増やした場合と同様に学習すべき パラメータの数は増加します。しかし、基本モジュールをカスケードに接続した場合の学習における パラメータ更新時間は層数に比例して増加します。それに対して、各層内のフィルタカーネルの更新は GPU等の並列演算装置を利用することによって並列に処理することが可能です。 もし、畳込み層内のチャネル数を増やすことで層数の増加と同等、 あるいはそれ以上の認識精度が得られるとすれば、並列処理の特性を活かす有効な手段となります。 幾つかのベンチマーク用データセットに対する評価実験の結果から、 層数を抑えてチャネル数を増やしたWide ResNetが、同等のパラメータ数を持つ従来の深層ResNet よりも認識精度の向上とともに学習時間の数倍の高速化が可能となったことが報告されています。 図5-5は、Wide ResNetの基本となるモジュールの構成を示したものです。
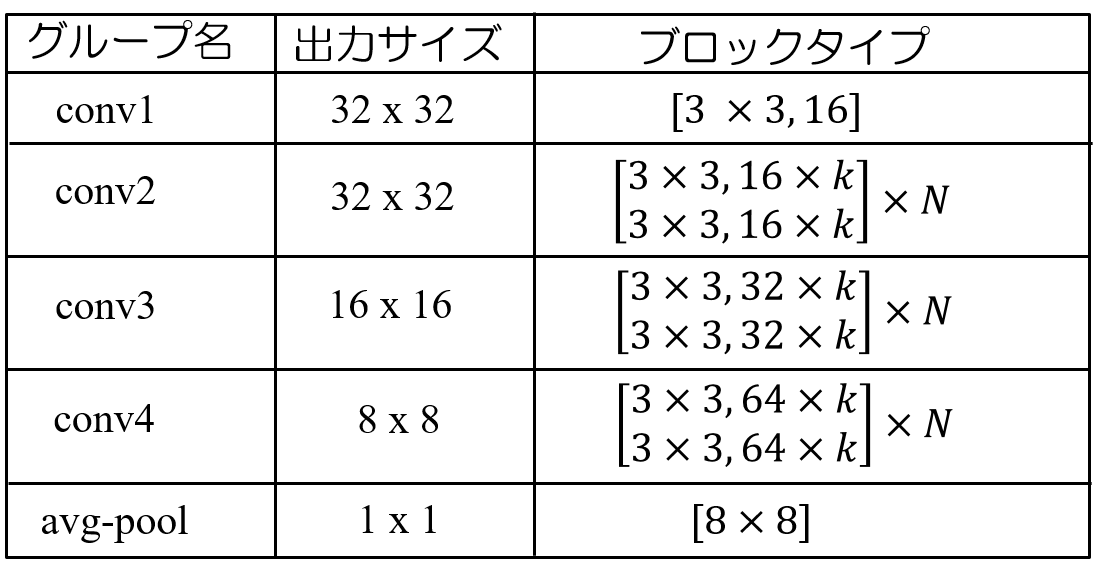
図5-5の構成は、CIFAR-10(CIFAR-100)を学習用データセットとして検討されたもので、 32x32画素の3チャネルカラー画像を入力としたものです。同図において、基本モジュール表現の仕方は 図5-4と同様ですが、チャネル数表現の中に新たなパラメータ$k$が導入されています。 また、基本モジュール 次回以降に、ResNetを用いた画像識別サンプルプログラムについて眺めてみたいと思います。
参考文献
- [1] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun,"Deep Residual Learning for Image Recognition",
https://arxiv.org/abs/1512.03385 - [2] Kaiming He, Xiangyu Xhang, Shaoqing Ren, and Jian Sun,"Identity Mappings in Deep Residual Networks",
https://arxiv.org/abs/1603.05027 - [3] "Residual Network(ResNet)の理解とチューニングのベストプラクティス",
https://deepage.net/deep_learning/2016/11/30/resnet.html - [4] Sergey Zagoruyko, and Nikos Komodakis,"Wide Residual Networks",
https://arxiv.org/abs/1605.07146