可視化は、出力が2次元特徴マップで表されるレイヤーを対象とします。 基本的には、作成した全体ネットワークの入力層から可視化したいレイヤーの出力 までを新たなネットワークモデルとして定義し、特定の入力をこの新たなモデルに 入力したときの新モデルからの出力を予測(predict)します。 このとき、可視化したいレイヤーを指定する方法としては、全体ネットワークを 作成した段階でKerasによって付与されるレイヤーモデルの名前か、あるいは レイヤー定義時に明示的に付与した名前を用いてレイヤーの指定が可能です。 Kerasによって付与されるレイヤーの名称は、Modelクラスのメソッドであるsummary() 関数によって知ることができます。
最初は、CNNを用いたオートエンコーダにおいて、その中間レイヤーの結果を可視化する
場合についてまとめました。
以下は、サンプルプログラムですが、説明のために幾つかのブロックに区切ってあります。
まずは、必要なパッケージのインポート部分です。
#畳み込みNNシステムに必要なパッケージのインポート
from keras.layers import Input, Conv2D, MaxPooling2D, UpSampling2D
from keras.models import Model
from keras.datasets import mnist
import numpy as np
続いて、ネットワークの構造を定義する部分です。 学習するデータはMNIST数字パターンで、そのサイズは(28画素 x 28画素 x 1チャネル)です。
#CNNによるオートエンコーダの定義
input_img = Input(shape=(28,28,1))
#エンコーダ部の各レイヤー
x1 = Conv2D(16,(3,3), activation = 'relu', padding = 'same')(input_img)
x2 = MaxPooling2D((2,2),strides=None)(x1)
x3 = Conv2D(8,(3,3), activation = 'relu', padding = 'same')(x2)
x4 = MaxPooling2D((2,2),strides = None)(x3)
x5 = Conv2D(8, (3, 3), activation = 'relu', padding = 'same')(x4)
#サイズを偶数にするためにゼロパディングを実施
en = MaxPooling2D((2,2), strides = None, padding = "same")(x5)
#
#デコーダ部の各レイヤー
xx = Conv2D(8,(3,3), activation = 'relu', padding = 'same')(en)
xx = UpSampling2D((2,2))(xx)
xx = Conv2D(8,(3,3), activation = 'relu', padding = 'same')(xx)
xx = UpSampling2D((2,2))(xx)
xx = Conv2D(16,(3,3),activation = 'relu')(xx)
xx = UpSampling2D((2,2))(xx)
de = Conv2D(1,(3,3),activation = 'sigmoid', padding = 'same')(xx)
#入力と出力を明示してネットワークモデルのインスタンスを生成
autoencoder = Model(inputs=input_img, outputs=de)
#モデルの学習環境の設定
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
(x_train,_),(x_test,_) =mnist.load_data()
##データの正規化とデータ構造の変更
x_train = x_train.astype('float32')/255.0
x_test = x_test. astype('float32')/255.0
x_train = np.reshape(x_train,(len(x_train), 28,28,1)) #channels_last
x_test = np.reshape(x_test, (len(x_test), 28,28,1)) #channels_last
#
autoencoder.fit(x_train, x_train, epochs=30, batch_size=128,
shuffle=True,validation_data=(x_test,x_test) )
##学習した重み係数を保存
autoencoder.save_weights('conv_autoencoder.h5')
def visualize_images(x_test, decoded_img, no):
import matplotlib.pyplot as plt
plt.figure(figsize=(10,2)) #表示域全体サイズ指定: 2 x 10(インチ)
for i in range(no):
#元画像を表示
ax1 = plt.subplot(2, no, i+1) #表示枠(2,no)のi+1番目を選択
plt.imshow(x_test[i].reshape(28,28),cmap='gray')
ax1.get_xaxis().set_visible(False)
ax1.get_yaxis().set_visible(False)
#復号化された画像を表示
ax2 = plt.subplot(2,no,i+1+no)
plt.imshow(decoded_img[i].reshape(28,28),cmap='gray')
ax2.get_xaxis().set_visible(False)
ax2.get_yaxis().set_visible(False)
plt.show()
n = 10
decoded_images = autoencoder.predict(x_test[0:n])
visualize_images(x_test,decoded_images, n)
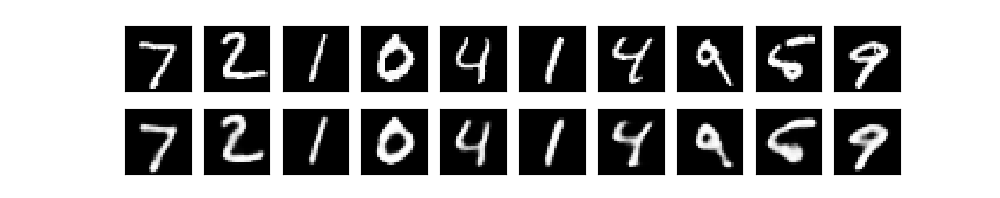
上記の可視化はオートエンコーダの出力パターンを対象としましたが、ネットワーク
構築作業においては、入出力レイヤー層以外の層の結果を評価・検証したいことが
少なくありません。
このようなことを踏まえ、評価したいレイヤーの指定方法や、
評価手段について考えてみます。
まず、定義したネットワークモデルの全体像を表示してくれるModelクラスのメソッド
であるsummary()に注目しましょう。上で作成したModelクラスのインスタンスである
"autoencoder"に対して、
autoencoder.summary()
を実行すると、以下ような出力が得られます。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 28, 28, 1) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 28, 28, 16) 160
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 14, 14, 16) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 14, 14, 8) 1160
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 7, 7, 8) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 7, 7, 8) 584
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 4, 4, 8) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 4, 4, 8) 584
_________________________________________________________________
up_sampling2d_1 (UpSampling2 (None, 8, 8, 8) 0
_________________________________________________________________
conv2d_5 (Conv2D) (None, 8, 8, 8) 584
_________________________________________________________________
up_sampling2d_2 (UpSampling2 (None, 16, 16, 8) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 14, 14, 16) 1168
_________________________________________________________________
up_sampling2d_3 (UpSampling2 (None, 28, 28, 16) 0
_________________________________________________________________
conv2d_7 (Conv2D) (None, 28, 28, 1) 145
=================================================================
Total params: 4,385
Trainable params: 4,385
Non-trainable params: 0
_________________________________________________________________
各行はモデルを構成するそれぞれのレイヤーに関する
情報を表します。各レイヤー情報は3つのコラム、すなわち
固有名(レイヤークラス)、Tensorサイズ、学習すべきパラメータ数
から構成されています。レイヤー名は明示的に指定しなければ、そのレイヤークラスを 表す接頭語と順番とを組み合わせた固有名がKerasシステムによって与えられます。 上記のレイヤー名は全てKerasが付けた名前です。Tensorのサイズは、入力データの サイズや、中間レイヤーで出力される特徴マップのサイズを示しています。この サイズを見ることによって、 畳み込み処理におけるフィルタカーネルの大きさやストライド、 あるいはプーリング時のフィルタサイズ等と、 入出力マップサイズとの関係を確認することができます。 最後のParam欄はそれぞれのレイヤーで学習されるパラメータの数を示しています。 ここでは、レイヤーの名前に着目します。すなわち、ネットワークモデルのインスタンス を生成したのち、このモデルのレイヤーにアクセスする場合には、それぞれのレイヤー名 を用います。
モデルを生成した時点では、各レイヤーには実体としての出力は存在しません。 実際の画像データをモデルに入力して学習か予測を実行することで、 各レイヤーに出力が得られます。 ここでは、学習が済んだモデルに対して画像を入力し、特定のレイヤーからの出力を 観測することを考えます。出力を観測するレイヤーとして、レイヤー名'conv2d_1'と しました。 与えられた入力画像に対して予測(ここでは画像の符号化/復号化)結果を観測するために、 観測したいレイヤーを最終レイヤーとする新たなモデルを定義し、 このモデルの入力データに対する予測を実行します。 以上の処理をスクリプトとして表すと以下のようになります。
fmap_model = Model(inputs = autoencoder.input,
outputs = autoencoder.get_layer('conv2d_1').output)
fmap_images = fmap_model.predict(x_test[:5])
visualize_feature_map(fmap_images, 'conv2d_1',1)

参考までに、visualize_feature_map()関数は以下です。
######### 特定レイヤー各チャネルの特徴マップ表示 ###########
def visualize_feature_map(fmap, title, index, channels_first=False):
#fmap : 特徴マップ配列
#title: layerの名前
#index: 指定された入力番号の特徴マップを表示(index < no)
if channels_first == True:
fmap = fmap.transpose(0,2,3,1) #channels_lastへ変換
no,height, width, channel = fmap.shape[0:4]
print(f'height:{height} width:{width} channel: {channel}')
flag = True
col,row = 8,8 #縦横表示パターン数
pl_width = 8 #表示域横長(単位:インチ)
pl_height= 8 #表示域縦長(単位:インチ)
count = 0
while flag :
fig = plt.figure(figsize=(pl_width, pl_height))
fig.suptitle(f'Feature map: {title}({count})')
for i in range(row):
if flag == False:
break
for j in range(col):
ax = fig.add_subplot(row, col, i*col+j+1)
ax.imshow(fmap[index,:,:,count], cmap='gray')
count += 1
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
if count >= channel :
flag = False
break
plt.show()
#visualize_feature_map終了
次は、特徴マップ数が比較的多い場合の例について可視化してみます。参考にした プログラムは、以下のURLで公開されているU-netを利用した通行人検出/セグメンテーション システムです。プログラムのソースコードとともに学習用/テスト用画像およびそれらの ラベル画像がともに提供されています。
http://ni4muraano.hatenablog.com/entry/2017/08/10/101053
このシステムで定義されているu-netの先頭の一部分を示したものが以下のネットワーク モデルです。 全体は65層で構成されるモデルですが、ここでは畳み込み層"conv2d-1"と"conv2d-2"の 2つの層で得られる特徴マップについて可視化してみます。
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) (None, 256, 256, 3) 0
__________________________________________________________________________________________________
zero_padding2d_1 (ZeroPadding2D (None, 258, 258, 3) 0 input_1[0][0]
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 128, 128, 64) 3136 zero_padding2d_1[0][0]
__________________________________________________________________________________________________
leaky_re_lu_1 (LeakyReLU) (None, 128, 128, 64) 0 conv2d_1[0][0]
__________________________________________________________________________________________________
zero_padding2d_2 (ZeroPadding2D (None, 130, 130, 64) 0 leaky_re_lu_1[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 64, 64, 128) 131200 zero_padding2d_2[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 64, 64, 128) 512 conv2d_2[0][0]
__________________________________________________________________________________________________
leaky_re_lu_2 (LeakyReLU) (None, 64, 64, 128) 0 batch_normalization_1[0][0]
__________________________________________________________________________________________________
zero_padding2d_3 (ZeroPadding2D (None, 66, 66, 128) 0 leaky_re_lu_2[0][0]
__________________________________________________________________________________________________
conv2d_3 (Conv2D) (None, 32, 32, 256) 524544 zero_padding2d_3[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 32, 32, 256) 1024 conv2d_3[0][0]
: : :
: : :
############ 必要なパッケージと関数のインポート ##############
import numpy as np
import keras
from keras.models import Model
from unet import UNet
from unet_main import load_X
############ 予測対象画像の格納フォルダへのパス ##############
testX_path = './PedCut2013_SegmentationDataset/data/testData/left_images'
input_channels = 3 #入力:BGR3チャンネル
output_channels = 1 #出力:白黒階調1チャンネル
first_layer_filters = 64 #最初のフィルタ数:64,
network = UNet(input_channels, output_channels, first_layer_filters)
whole_model = network.get_model() #Modelオブジェクト:全体モデル
whole_model.load_weights('unet_weights.hdf5') #全体モデルの重み読込
layer_name1 = 'conv2d_1' #結果を出力するレイヤー名
layer_name2 = 'conv2d_2'
#入力レイヤーから出力レイヤーまでの新たなモデル定義
slice_model1= Model(inputs = whole_model.input,
outputs = whole_model.get_layer(layer_name1).output)
slice_model2= Model(inputs = whole_model.input,
outputs = whole_model.get_layer(layer_name2).output)
X_test, file_names = load_X(testX_path)
no=10
Y_pred1 = slice_model1.predict(X_test[0:no])
Y_pred2 = slice_model2.predict(X_test[0:no])
visualize_feature_map(Y_pred1, layer_name1, 4) #5番目の画像の特徴マップ選択
visualize_feature_map(Y_pred2, layer_name2, 4)

.png)
.png)